広告・SEO・SNS・PRをどう組み合わせるべきかを解説
顧客獲得を最大化する集客戦略PESO Integrated Growth Strategy
資料を無料ダウンロード
RAGとは?生成AIとの違いや仕組み・メリット・活用例を解説
その他 2026.06.25

RAG(Retrieval-Augmented Generation)とは、あらかじめ整備した自社専用の知識ベース(社内文書・FAQ・マニュアルなど)を生成AIに検索・参照させることで、回答の精度を高める仕組みです。日本語では「検索拡張生成」と訳されます。
最近の生成AI(ChatGPTやClaudeなど)にはWeb検索機能が搭載されており、公開情報であれば調べながら回答できます。しかし、自社の就業規則や製品マニュアル、社内の申請手順といった非公開の情報はWeb上に存在しないため、検索機能があっても正確には答えられません。また、学習データに含まれない内容についてもっともらしい誤答を返してしまう「ハルシネーション」のリスクも残ります。
RAGはこうした課題を補うアプローチです。社内文書やデータベースを専用の知識ベースとして整備し、質問に応じてその中から関連情報を検索・参照させることで、公開されていない独自情報にも対応でき、回答の正確性と信頼性を高められます。
この記事では、RAGの仕組みを支える技術、通常の生成AIやファインチューニングとの違い、メリットと注意点、業務での活用例、導入の進め方、そして2026年の最新動向までを順番に解説します。
目次
RAGとは「検索してから答える」生成AIの仕組み
RAGは、ひとことで言えば「質問を受け取ったら、自社で整備した知識ベースの中から関連する文書を検索し、その内容を踏まえて回答を作る」仕組みです。
たとえば社員が「在宅勤務の申請方法を教えて」と質問したとき、RAGを組み込んだシステムは社内の勤怠規程や申請マニュアルを検索し、該当する記述を見つけてから回答を生成します。「この製品の返品条件は?」という問い合わせであれば、製品の利用ガイドやFAQを参照して答えます。
Web検索のように公開情報を探しに行くのではなく、あらかじめ登録しておいた自社の資料の中から答えの根拠を見つけるのがポイントです。
RAGという名前は、以下の3つの英単語の頭文字に由来しています。
- Retrieval(検索):質問に関連する情報を自社の知識ベースから取得する
- Augmented(拡張):取得した情報でAIの回答の根拠を補強する
- Generation(生成):補強された情報をもとに、自然な文章として回答を作り出す
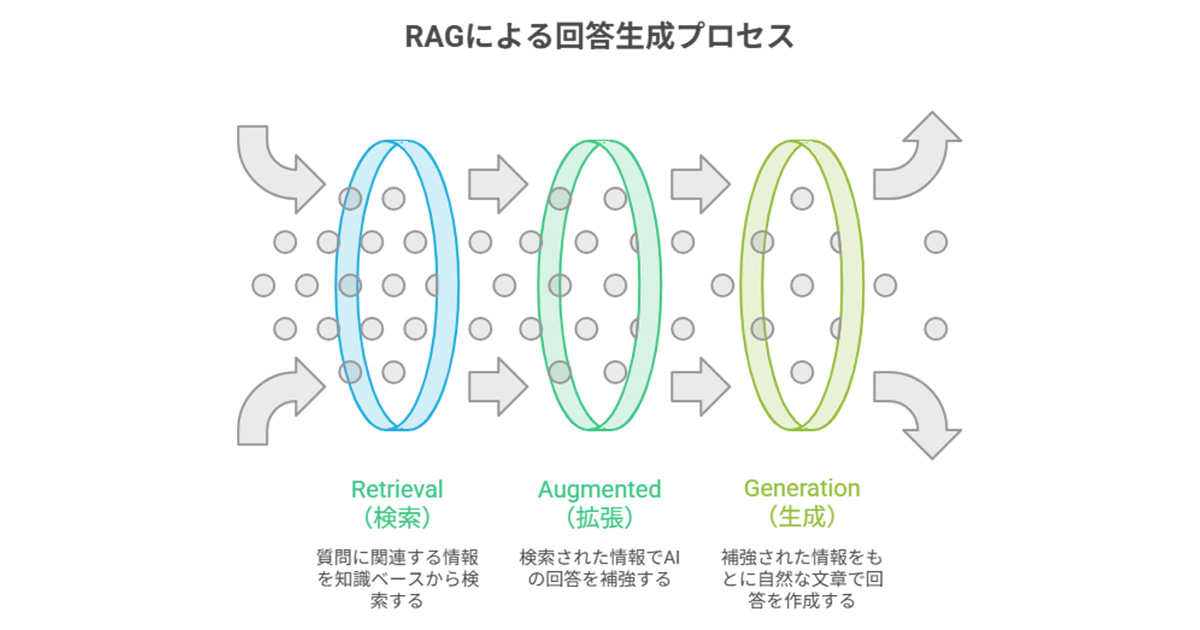
この3ステップが連動することで、生成AI単体では難しかった「根拠のある回答」を実現しやすくなります。
RAGが注目される背景には、Web検索付きの生成AIでも解決しきれない業務上の課題があります。
Web上に存在しない社内情報を参照できない「固有情報の不在」、学習時点以降の制度変更やルール改定に追従できない「最新性の欠如」、そして根拠なくもっともらしい回答を生成してしまう「ハルシネーション」です。RAGは、自社で管理・更新できる知識ベースを参照先とすることで、これらの課題に対応します。
RAGの仕組みを3ステップで解説
RAGの処理は大きく「知識ベースの準備」「検索」「回答生成」の3段階に分かれます。
ステップ1:知識ベースを準備する
まず、AIに参照させたい文書をあらかじめ整理し、検索できる状態にします。対象となるのは、社内FAQ、業務マニュアル、規程集、製品資料、過去の問い合わせ履歴などです。
ここで重要なのが「チャンキング」と「エンベディング(埋め込み)」という2つの処理です。
チャンキング
長い文書を検索しやすい単位(チャンク)に分割する作業です。たとえば、100ページある業務マニュアルをそのまま検索対象にしても、必要な箇所だけを取り出すのは困難です。章・節・段落などの意味のまとまりごとに分けることで、質問に合った部分だけを効率的に見つけられるようになります。
なお、チャンクの粒度(どこで区切るか)は回答精度に直結します。大きすぎると無関係な情報まで含まれてノイズになり、小さすぎると文脈が失われて回答の質が下がります。特に技術文書では、見出し階層や表の行列関係がチャンクの境界で分断されると、正しい情報を検索できなくなることがあります。文書の構造や用途に応じた調整が欠かせません。
エンベディング
分割したテキストを数値の列(ベクトル)に変換する処理です。人間が読む文章をAIが扱いやすい数値データに変換し、ベクトルデータベースと呼ばれる専用のデータベースに格納します。この変換によって、「意味が近い文章どうし」を計算で見つけられるようになります。たとえば「有給休暇の取り方」と「年次休暇の申請手順」は使っている単語が異なりますが、ベクトル化すれば意味の類似性を検出できるため、従来のキーワード一致型の検索では見逃していた関連文書も拾えるようになります。
ステップ2:質問に関連する情報を検索する
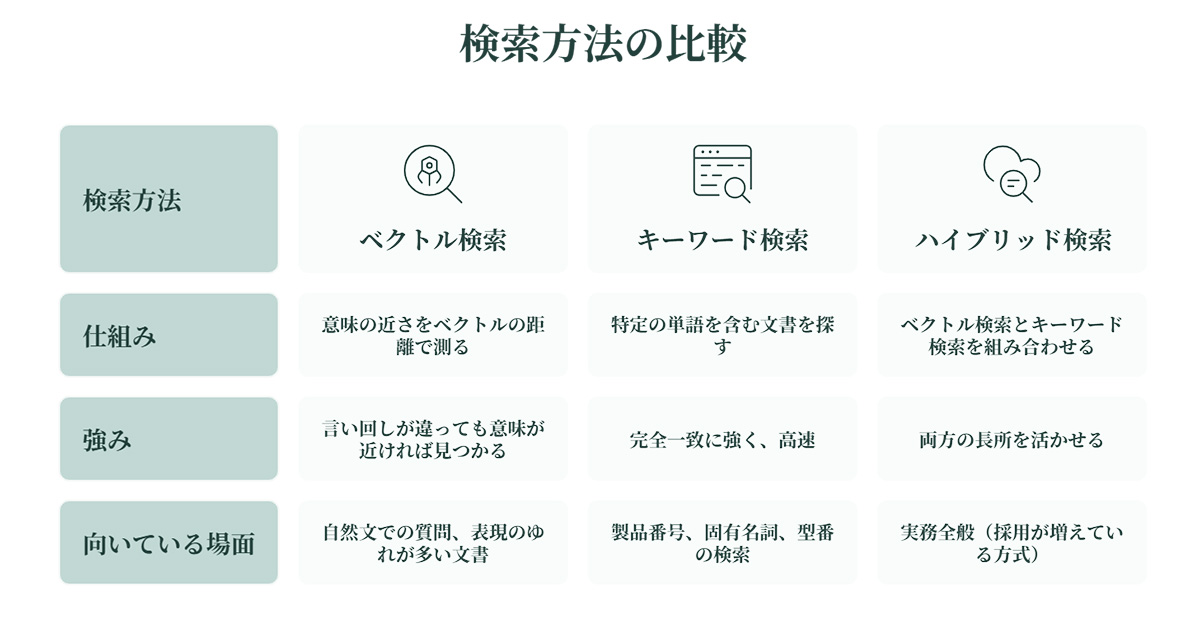
ユーザーが質問を入力すると、その質問文もベクトルに変換され、知識ベースの中から「意味的に近い」チャンクが検索されます。主な検索方法は以下の3種類です。
| 検索方法 | 仕組み | 強み | 向いている場面 |
| ベクトル検索 | 質問と文書の「意味の近さ」をベクトルの距離で測る | 言い回しが違っても意味が近ければ見つかる | 自然文での質問、表現のゆれが多い文書 |
| キーワード検索 | 特定の単語を含む文書を探す | 完全一致に強く、高速 | 製品番号、固有名詞、型番の検索 |
| ハイブリッド検索 | ベクトル検索とキーワード検索を組み合わせる | 両方の長所を活かせる | 実務全般(採用が増えている方式) |
ベクトル検索は意味の類似性に強い一方で、製品型番のような「完全一致が重要な情報」は苦手です。逆にキーワード検索は正確な語句のマッチングに優れますが、言い換え表現には対応しにくい弱点があります。そのため、実務ではベクトル検索とキーワード検索の両方を組み合わせるハイブリッド検索が主流になりつつあります。
この検索段階で適切な情報を取得できるかどうかが、最終的な回答品質を大きく左右します。RAGの精度改善を行う際も、まずこの検索フェーズのチューニングから着手するのが一般的です。
ステップ3:検索結果をもとに回答を生成する
検索で見つかった関連情報を、ユーザーの質問文とあわせてLLM(大規模言語モデル)に渡します。LLMは、受け取った情報を踏まえて質問に合った回答を自然な文章として生成します。
単に検索でヒットした文書を一覧で返すのではなく、複数の文書にまたがる内容を整理し、質問の意図に沿った形にまとめて答えるのがRAGの特徴です。たとえば「出張時の交通費精算と宿泊費の上限を教えて」という質問に対し、経費規程の交通費の条項と宿泊費の条項をそれぞれ検索し、両方の情報を統合してひとつの回答にまとめることができます。
さらに、参照した文書名や該当箇所を回答に併記する仕組みを設ければ、利用者が根拠を確認・検証することも可能になります。この「出典の透明性」は、業務利用においてRAGが信頼される理由のひとつです。
RAGとファインチューニング・LLM・検索エンジンの違い
RAGは既存の技術を置き換えるものではなく、LLMの弱点を検索で補う仕組みです。ここでは、特に混同されやすい3つの技術との違いを、比較されやすい順に整理します。
RAGとファインチューニングの違い:「何を参照するか」と「どう答えるか」
RAGとファインチューニングは、どちらも「LLMの出力を業務向けに改善する手法」ですが、改善のアプローチがまったく異なります。
| 比較項目 | RAG | ファインチューニング |
| やっていること | 回答時に自社の知識ベースを検索して参照させる | モデル自体を追加データで再学習させる |
| 情報の更新方法 | 知識ベースのデータを差し替えるだけ | モデルの再学習が必要(時間・コストがかかる) |
| 根拠の提示 | 参照元の文書名や該当箇所を示しやすい | モデル内部に知識が溶け込むため示しにくい |
| 得意なこと | 最新情報・社内文書への対応、根拠付き回答 | 回答の口調・形式・専門用語の使い方を安定させる |
ひとことで言えば、RAGは「何を参照して答えるか」を制御する仕組みで、ファインチューニングは「どのように答えるか」を調整する手法です。目的が異なるため、実務ではRAGで社内情報への対応を行い、ファインチューニングで回答のトーンや出力形式を整えるという併用も見られます。
RAGとLLM単体の違い:自社の非公開情報を参照できるかどうか
LLM単体(ChatGPTやClaudeをそのまま使う場合)は、学習済みの知識とWeb検索で回答を作ります。RAGとの違いは「自社専用の知識ベースを検索対象にできるかどうか」です。
| 比較項目 | RAG | LLM単体 |
| 参照できる情報 | 自社の知識ベース+学習済み知識 | 学習済み知識+Web上の公開情報 |
| 社内情報への対応 | 知識ベースに登録すれば対応可能 | 非公開情報は参照できない |
| ハルシネーション | 参照元があるぶんリスクが下がる | 根拠なく回答を生成する場合がある |
| 向いている場面 | 正確性・根拠が求められる業務 | 一般知識の説明、アイデア出し、壁打ち |
アイデア出しや一般的な質問であればLLM単体で十分ですが、社内ルールや製品仕様のように「正解がある問い」に答えさせたい場合はRAGが適しています。
RAGと検索エンジンの違い:情報を探すだけか、答えまで生成するか
検索エンジン(Google検索や社内検索ツール)は「関連しそうなページの一覧」を返すのに対し、RAGは「検索結果をもとにまとめた回答」を返します。
検索エンジンでは、利用者が複数のページを開いて読み比べ、自分で答えを組み立てる必要があります。RAGはこの手間を省き、複数文書の内容を統合した回答を自然な文章で提示します。ただし、RAGが検索を不要にするわけではありません。重要な判断をともなう場面では、AIの回答を鵜呑みにせず参照元を確認する作業が引き続き欠かせません。
RAGのメリットと注意点
RAGは業務での生成AI活用において多くの利点がありますが、導入・運用にあたって押さえておくべき注意点もあります。ここではメリットと注意点をあわせて整理します。
メリット
最新情報や社内情報を回答に反映できる
参照先の文書やデータベースを更新すれば、モデルを再学習させなくても新しい情報を回答に反映できます。
たとえば、4月に改定された社内の経費精算ルールを知識ベースに反映すれば、翌日から「出張時の日当はいくらか」という質問に新ルールで回答できるようになります。ファインチューニングでは同じ対応に再学習が必要で、数日から数週間のタイムラグが生じるケースも珍しくありません。
社内FAQ、業務マニュアル、規程、製品資料なども知識ベースに含められるため、自社固有の質問にも対応しやすくなります。
ハルシネーションのリスクを低減できる
生成AIの業務利用で最も懸念されるのが、事実と異なる内容をもっともらしく回答してしまうハルシネーションです。
RAGでは、AIが回答を作る際にかならず関連文書を参照するため、根拠のない情報を「創作」するリスクが下がります。ある調査では、RAGを導入した企業で誤回答率が平均40〜60%低下したという報告もあります。
完全にゼロにすることはできませんが、参照元が明確であるぶん、誤りの検出や修正もしやすくなります。
回答の根拠を示しやすい
回答に使った参照文書名や該当箇所を併記できるため、利用者が「この回答はどこに書いてあるのか」を確認しやすくなります。
たとえば法務部門で契約条件について質問した場合、回答とあわせて該当する規程の条文番号や文書名が表示されれば、担当者はその場で原文を確認できます。
法務・医療・金融など、説明責任が求められる業務では、この透明性が大きな価値を持ちます。
導入・運用コストを抑えやすい
ファインチューニングと比べると、モデルの再学習が不要なぶん、導入や情報更新にかかるコストを抑えやすい傾向があります。既存の社内文書やFAQをそのまま知識ベースとして活用できるため、ゼロから学習データを作成する必要がない点も、導入ハードルを下げる要因です。
<h3″>注意点
データ整備の質が回答精度を左右する
RAGの回答品質は、参照するデータの質に直結します。
たとえば、改定前の就業規則と改定後の就業規則が両方残っている状態では、AIが古い方を参照して誤った回答を返す可能性があります。似た内容の文書が重複している、表記がバラバラ、バージョン管理ができていない、といった状態も精度低下の原因になります。
RAGの導入は「AIに何を見せるか」のデータ整備が出発点であり、ここを怠ると、どれほど優れたモデルを使っても成果が出にくくなります。
検索設計の巧拙が成果を分ける
どんなに良い文書を用意しても、検索の設計が不十分だと必要な情報にたどり着けません。
チャンクの分割単位が大きすぎれば無関係な情報がノイズとして混入し、小さすぎれば文脈が失われて的外れな文書がヒットします。検索対象の範囲設定、検索方法の選択、検索結果の上位何件をLLMに渡すかといった設計判断も回答の質に影響します。
RAGの精度改善では、モデルの入れ替えよりも、この検索フェーズのチューニングが最も効果的であるケースが少なくありません。
継続的な運用とセキュリティ管理が必要
RAGは一度構築して終わりではなく、参照データの定期更新、回答精度のモニタリング、権限設定の見直しなど、継続的な運用が求められます。
また、社内文書や顧客情報を扱う場合は、部署や役職によって閲覧範囲を制御する、機密文書を知識ベースから除外する、操作ログを保持するといったセキュリティ面の設計も欠かせません。
「誰が・いつ・どの資料を更新するか」を事前にルール化しておかないと、古い情報に基づく回答がそのまま使われ続けるリスクがあります。
RAGの主な活用例
RAGは「参照すべき文書がある業務」と相性の良い仕組みです。ここでは、代表的な活用シーンを具体的な利用イメージとともに紹介します。
社内ナレッジ検索・ヘルプデスク
就業規則、経費精算、各種申請手続き、勤怠管理、福利厚生の利用条件など、社内の問い合わせに対し、関連するマニュアルやFAQを参照しながら回答します。
たとえば「育児休業の取得条件を教えて」という質問に対し、人事規程の該当条項を検索し、取得要件や申請手順を自然な文章で回答するイメージです。社員が自分で資料を探す時間を削減でき、管理部門への定型的な問い合わせの件数軽減にもつながります。
大手金融機関では、130万件超の社内文書をRAGで横断検索できる仕組みを構築した事例も報告されています。
カスタマーサポート・問い合わせ対応
顧客からの質問に対し、FAQ・製品マニュアル・過去のサポート履歴を参照して回答するチャットボットに活用されています。
「商品の返品方法を知りたい」「パスワードを忘れた場合の対処法は?」といった定型的な問い合わせをAIが一次対応することで、オペレーターは複雑な案件に集中できるようになります。従来はオペレーターの経験や知識によって対応品質にばらつきがありましたが、RAGでは全員が同じ参照資料に基づいて回答するため、新人でもベテランに近い対応品質を実現しやすくなります。
営業支援・提案準備
営業担当者が商談前に製品仕様、導入事例、料金表、契約条件、競合との比較情報などをすばやく確認したい場面に向いています。
「A社向けの提案に使える導入事例はあるか」「この製品の最新の価格改定内容は?」といった質問に対し、複数の資料を横断して必要な情報を整理できるため、提案資料の作成時間が短縮されます。属人的になりがちな営業ナレッジを組織全体で共有する基盤としても機能します。
調査・レポート作成の補助
社内資料や公開情報をもとに、調査結果の要約やレポートの下書きを作成する用途にも使えます。
たとえば「過去1年間の顧客クレームの傾向をまとめて」という依頼に対し、問い合わせ履歴を検索・分類して要点を整理するといった作業をAIが補助します。人が一から資料を読み込む手間を減らせる一方、最終的な正確性の確認や判断は人が行う前提での活用が基本です。
なお、RAGは「参照すべき文書が整備されていて、回答に根拠が求められる業務」で真価を発揮します。逆に、参照すべき元データがほとんどない業務や、自由な発想を重視するブレインストーミングのような用途では、RAGの強みは出にくくなります。
RAGの導入ステップと事前に確認すべきポイント
RAGの導入は、AIモデルの選定だけでなく、参照データの設計と運用体制の整備が成果を左右します。ここでは導入の流れに沿って、各ステップで押さえるべきポイントを解説します。
ステップ1:参照させる文書を整理する
まずはFAQ、規程、マニュアル、製品資料など、AIに参照させたい文書を洗い出します。
このとき重要なのが「AIに何を見せるか」の選別です。最新版はどれか、不要な古い資料が混ざっていないか、機密情報をどう扱うかをこの段階で整理します。社内資料が複数のシステムに散在している場合は、まず対象文書の棚卸しから始める必要があります。
RAGの精度はモデルの性能以上に参照データの品質に左右されるため、このステップが成否の土台になります。
ステップ2:文書を検索しやすい形に加工する
<p”>長い文書をチャンクに分割し、エンベディングでベクトルに変換してベクトルデータベースに格納します。チャンクの粒度は文書の性質に応じて調整が必要です。 <p”>たとえばFAQのように1問1答の構造が明確な文書は質問と回答のペアを1チャンクにできますが、業務マニュアルのように文脈が連続する文書は、章や節の単位で分割したほうが検索精度が高まる傾向があります。
ステップ3:検索と回答生成の仕組みを設計する
検索方式(ベクトル検索・キーワード検索・ハイブリッド検索)の選定、検索結果の上位何件をLLMに渡すかの設定、回答とあわせて参照元を表示する仕組みの実装などを行います。
「小さく始めて改善する」アプローチが効果的で、まずは1つの部署や1つのユースケース(たとえば「人事規程に関するFAQ対応」など)に絞って構築し、精度を確認しながら範囲を広げていくのが成功しやすい進め方です。
ステップ4:回答精度を検証し、運用体制を整える
実際の質問を使って、適切な文書を検索できているか、回答は質問の意図に合っているかを確認します。あわせて、以下の運用設計も整備しておくことが重要です。
- 更新ルール:制度や仕様が変わったとき、誰が・いつ・どの資料を更新するかを決めておく。未定のまま運用すると、古い情報に基づく回答がそのまま使われ続けるリスクがある。
- 権限管理:部署や役職による閲覧範囲の制御、機密文書の除外、操作ログの保持など、情報管理の仕組みを設計する。
- 検証フロー:業務担当者が回答の正確性を定期的にレビューする体制と、誤答を検知した際の修正手順を用意する。
RAGは「完璧に準備してから始める」よりも、小さく始めて学びながら改善を繰り返すアプローチが最も成果につながりやすい技術です。
RAGの進化:2026年の最新動向
RAGの技術は急速に進化しています。従来の基本形(Naive RAG)は「質問→検索→回答」というシンプルな流れでしたが、精度や対応範囲を高めるためにさまざまな発展型が登場しています。
| 種類 | 概要 | 従来のRAGとの違い |
| Advanced RAG | クエリ最適化、リランキング、高度なチャンキング戦略で検索精度を向上させる発展型 | 検索の前後に精度を高める工夫を追加 |
| GraphRAG | 文書間の関係性をナレッジグラフで構造化し、概念のつながりを活用する手法 | 複数文書にまたがる複雑な質問に対応可能 |
| Agentic RAG | AIエージェントが「何を調べるべきか」を自律判断し、検索→評価→追加検索を能動的に繰り返す | 単発検索では答えにくい複合的な質問に対応 |
| マルチモーダルRAG | テキストに加え、画像・表・図・PDF内の図表も検索対象にする | 視覚的な情報も含めた横断検索が可能に |
Advanced RAG
現時点で最も実務導入が進んでいる発展型です。ユーザーの質問文をそのまま検索に使うのではなく、検索に適した形に書き換える「クエリ最適化」や、検索結果を関連度の高い順に並び替える「リランキング」を組み合わせることで、基本形よりも的確な情報を拾えるようになります。
GraphRAG
2024年にMicrosoft Researchが発表したことで大きな注目を集めました。通常のベクトル検索では文書を1つずつ独立して扱いますが、GraphRAGでは文書間の関係性をナレッジグラフ(知識グラフ)として構造化します。「A部門の規程とB部門の規程で矛盾する点はあるか」のような、複数文書を横断する問いに強いのが特徴です。
Agentic RAG
2025年以降もっとも注目度が高いアプローチです。従来のRAGが「質問→1回の検索→回答」という受動的な流れだったのに対し、Agentic RAGではAIエージェントが自律的に「この情報だけでは不十分だから追加で調べよう」と判断し、複数回の検索や外部ツールの呼び出しを行いながら回答を組み立てます。
マルチモーダルRAG
テキストだけでなく画像・表・図・PDF内のグラフなども検索対象に含める仕組みです。たとえば製品の写真を見せながら「この部品の交換手順は?」と質問するような使い方が実現しつつあります。技術文書や設計図面を多用する製造業での実用化が期待されています。
こうした技術の進化に伴い、RAGは単なるQ&Aツールから、企業全体のナレッジ基盤へと位置づけが変わりつつあります。
まとめ
RAGとは、自社で整備した知識ベース(社内文書・FAQ・マニュアルなど)を生成AIに検索・参照させ、その内容を踏まえて回答を生成する仕組みです。
初めてRAGに触れる方は、「AIに資料を見せてから答えさせる仕組み」と覚えておけば十分です。そのうえで「参照すべき文書があり、回答に根拠が求められる業務かどうか」を判断基準にすると、導入の向き不向きが見えてきます。
RAGの導入や活用についてお悩みの方は、ぜひパンタグラフにご相談ください。貴社の課題に合わせて、最適なご提案をいたします。

pagetop